Matrix Multiplication Cuda Python
Matrix multiplication tutorial Naive CUDA kernel. Multiplication of two matrices X and Y is defined only if the number of columns in X is equal to the number of rows Y.
20 Examples For Numpy Matrix Multiplication Like Geeks
Y bw cuda.

Matrix multiplication cuda python. The values of Matrix A. Y bw cuda. I yi alphaxi yi Invoke serial SAXPY kernel.
Python matmatmuloclpy matrix A. Float Aelement a ty MATRIX_SIZEs k. Matrix multiplication is simple.
340x340 F JS OpenCL SQLite Matrix size. Well start with a very simple kernel for performing a matrix multiplication in CUDA. X bh cuda.
The input follows this pattern. The number of columns of Matrix A. X ty cuda.
X by cuda. If ty. Now we will have a look at how to use Kernel Tuner to find the best performing combination of.
Our first example will follow the above suggested algorithm in a second example we are going to significantly simplify the low level memory manipulation required by CUDA. Y i tx bx bw j ty by bh 3D grid of 3D blocks tx cuda. It ensures that extra threads do not do any work.
Y bx cuda. We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard. Lets say we want to multiply matrix A with matrix B to compute matrix C.
Here are a couple of ways to implement matrix multiplication in Python. We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU. Float Pvalue 0.
Anpones 20150000dtypenpfloat32 Bnpones 1307250000dtypenpfloat32 Cnpones 20307250000dtypenpfloat32 I skipped one dimension in A and B because it is not necessary for the computation. Pvalue is used to store the element of the matrix. Using shared memory.
Numba supports CUDA GPU programming by directly compiling a restricted subset of Python code into CUDA kernels and device functions following the CUDA execution model. NumPy arrays are transferred between the CPU and the GPU automatically. Y bd cuda.
Leave the values in this cell alone M 128 N 32 Input vectors of MxN and NxM dimensions a nparangeMNreshapeMNastypenpint32 b nparangeMNreshapeNMastypenpint32 c npzerosM Mastypenpint32 d_a cudato_devicea d_b cudato_deviceb d_c cudato_devicec NxN threads per block in 2 dimensions block_size NN MxMNxN blocks per grid in 2 dimensions grid_size intMNintMN import numpy as np from numba import cuda types ucuda. Type int Type float C SIMD CUDA Python Kotlin Rust C C GO x64 NASM PHP Julia Excel VBA Matrix size. The values of Matrix B.
X by cuda. The formula used to calculate elements of d_P is. 21 The CUDA Programming Model.
340x340 TCL Lua Zig. Assume A is a p w matrix and B is a w q matrix So C will be p q matrix. X bh cuda.
Y bz cuda. Y tz cuda. Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop void saxpy_serialint n float alpha float x float y forint i 0.
The number of lines of Matrix B. Kernels written in Numba appear to have direct access to NumPy arrays. The number of lines of Matrix A.
The above condition is written in the kernel. X ty cuda. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK.
If X is a n x m matrix and Y is a m x l matrix then XY is defined and has the dimension n x l but YX is not defined. In this video we look at writing a simple matrix multiplication kernel from scratch in CUDAFor code samples. Tuning a naive kernel.
Matrix matrix multiplication Our running example will be the multiplication of two matrices. Matrix Multiplication using GPU CUDA Cuda Matrix Implementation using Global and Shared memory. MatrixMultiplication System stats for the compared run.
The number of columns of Matrix B. Float Belement b k MATRIX_SIZEs tx. In order to resolve any confusion this is actually a 3D matrix by 3D matrix multiplication.
340x340 XSLT Matrix size. Z bx cuda. A typical approach to this will be to create three arrays on CPU the host in CUDA terminology initialize them copy the arrays on GPU the device on CUDA terminology do the actual matrix multiplication on GPU and finally copy the result on CPU.
In this video we go over basic matrix multiplication in CUDA. That is computed by the thread.

Cuda Python Matrix Multiplication Programmer Sought
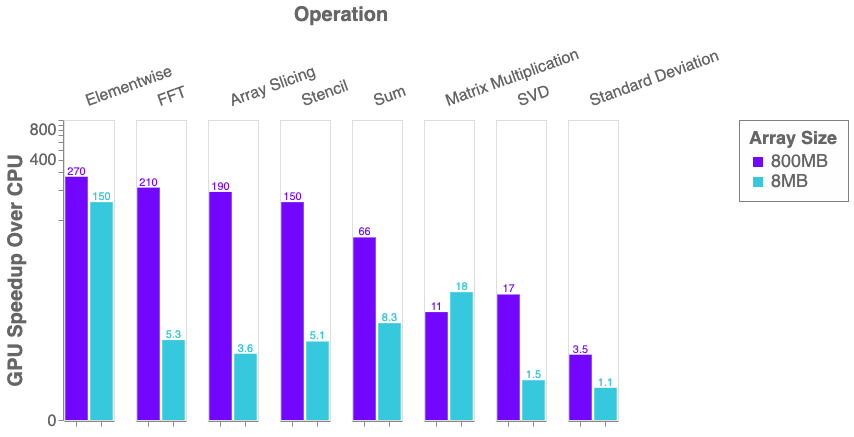
Python Performance And Gpus A Status Update For Using Gpu By Matthew Rocklin Towards Data Science

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

The Best Gpus For Deep Learning In 2020 An In Depth Analysis

Pin On Useful Links
Https Arxiv Org Pdf 1901 03771

Parallel Computing For Data Science With Examples In R C And Cuda Norman Matloff Obuchenie Programmirovanie Shpargalki

How To Increase Speed Transfer Of Matrices Gpu Cpu For Matrix Multiplication It Is The Limiting Factor Cuda Programming And Performance Nvidia Developer Forums

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
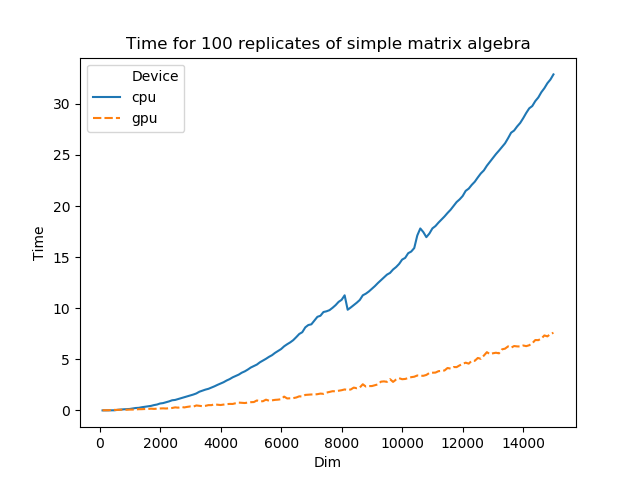
Pycuda Series 2 A Simple Matrix Algebra And Speed Test Liang Xu

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
Http Games Cmm Uchile Cl Media Uploads Courses 2016 Informe Garrido Mario Pdf

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Pin On Useful Links

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
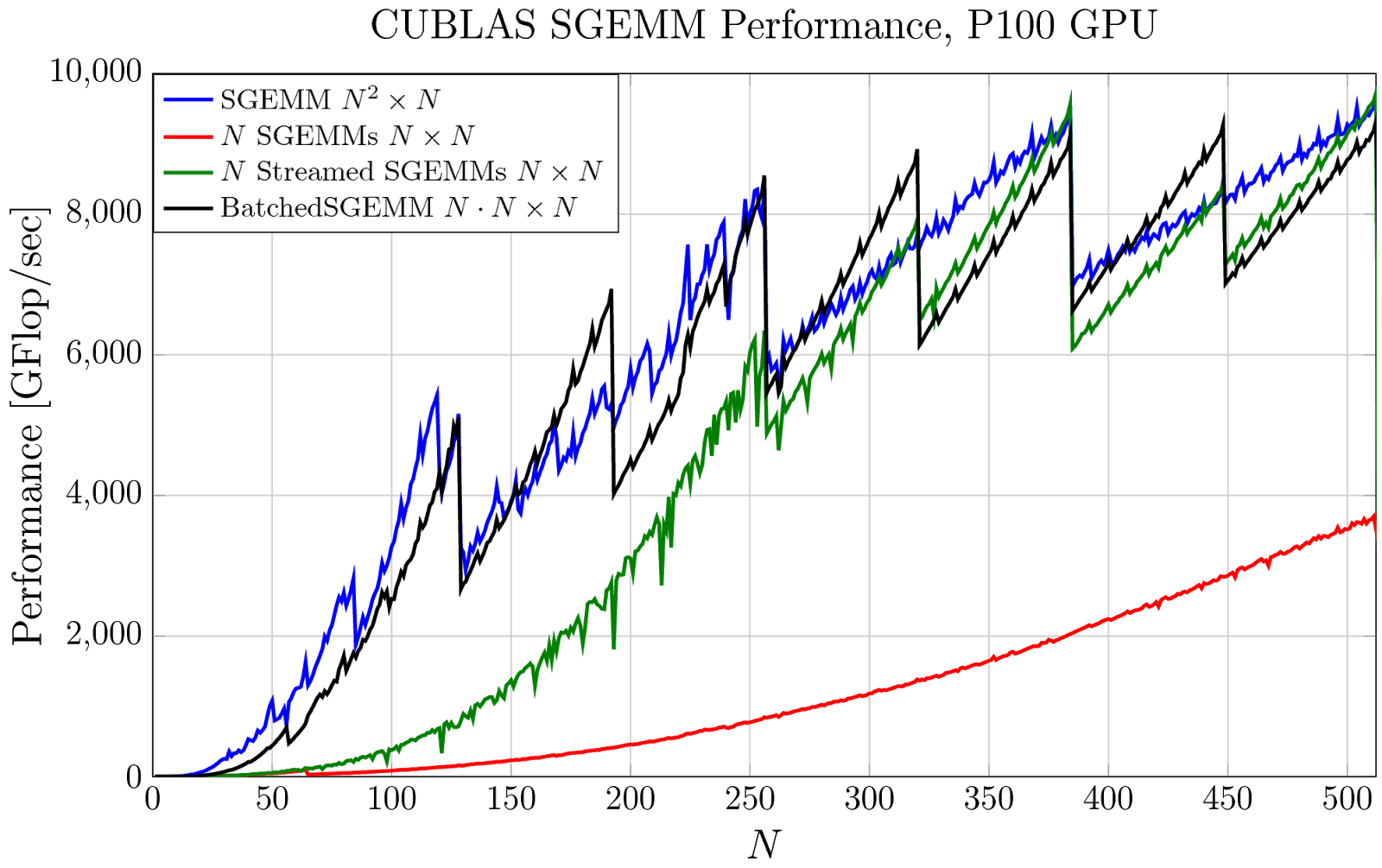
Pro Tip Cublas Strided Batched Matrix Multiply Nvidia Developer Blog

Cuda Python Matrix Multiplication Programmer Sought

Cuda Python Matrix Multiplication Programmer Sought

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation