Cuda Matrix Multiplication Zero
The driver on Tegra does not move data for unified memory it. This is likely why the matrix multiply is running slower with zero-copy memory.

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
Void init_matrix_zero matrix m int i j.

Cuda matrix multiplication zero. Copy path Cannot retrieve contributors at this time. 1 Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop. Int Row blockIdxy blockDimy threadIdxy.
For i 0. CUDA_R_16F CUDA_R_16BF CUDA_R_8I each column must have at least two non-zero values every four elements CUDA_R_32F each column must have at least one non-zero value every two elements The correctness of the pruning result matrix A B can be check with the function cusparseLtSpMMAPruneCheck. Unified memory does the cache management to ensure data coherence.
The matmulpy is not a fast implementation of matrix multiplication for cuda. Printf Usage -devicen n 0 for deviceID n. One platform for doing so is NVIDIAs Compute Uni ed Device Architecture or CUDA.
Writefile matmul_naivecu define WIDTH 4096 __global__ void matmul_kernel float C float A float B int x blockIdx. It is implemented on top of the NVIDIA CUDA runtime which is part of the CUDA Toolkit and is designed to be called from C and C. Y block_size_y threadIdx.
April 2017 Slide 15 Matrix-matrix multiplication with blocks Ckl i1 N Aki Bil C kl i1 N2 Aki Bil iN2 1 N Aki Bil For each element Set result to zero For each pair of blocks Copy data Do partial sum Add result of partial sum to total. Printf Matrix Multiply Using CUDA - Starting. For int k 0.
Element ij 00 Multiplies matrix a with matrix b storing the result in matrix result The multiplication algorithm is the On3 algorithm void mm matrix a matrix b matrix result int i j k. Refer to vmppdf for a detailed paper describing the algorithms and testing suite. Printf -wBWidthB -hBHeightB Width x Height of Matrix B n.
GPUProgramming with CUDA JSC 24. It is assumed that the student is familiar with C programming but no other background is assumed. The goal of this project is to create a fast and efficient matrix-vector multiplication kernel for GPU computing in CUDA C.
Both CPU and GPU caches are bypassed for zero-copy memory. Cuda-matrix-vector-multiplication zero_kernelscu Go to file Go to file T. Matrix-Vector Multiplication Using Shared and Coalesced Memory Access - uysalerecuda-matrix-vector-multiplication.
The library targets matrices with a number of structural zero elements which represent 95 of the total entries. If Row numCRows Col numCColumns float. Execute the following cell to write our naive matrix multiplication kernel to a file name matmul_naivecu by pressing shiftenter.
For i 0. If you need high performance matmul you should use the cuBLAS API from pyculib. We use the example of Matrix Multiplication to introduce the basics of GPU computing in the CUDA environment.
Matrix-Vector Multiplication Using Shared and Coalesced Memory Access. X block_size_x threadIdx. Int y blockIdx.
Go to line L. It is more of a demonstration of the cudajit feature. Printf -wAWidthA -hAHeightA Width x Height of Matrix A n.
Matrix multiplication is a key computation within many scientific applications. I for j 0. This policy decomposes a matrix multiply operation into CUDA blocks each spanning a 128-by-32 tile of the output matrix.
The thread block tiles storing A and B have size 128-by-8 and 8-by-32 respectively. Float sum 00. Define TILE_WIDTH 16 Compute C A B __global__ void matrixMultiplyfloat A float B float C int numARows int numAColumns int numBRows int numBColumns int numCRows int numCColumns Insert code to implement matrix multiplication here float Cvalue 00.
Int Col blockIdxx blockDimx threadIdxx. If checkCmdLineFlag argc const char argv help checkCmdLineFlag argc const char argv. It is also comparing to a highly optimized CPU version in numpy MKL matmul if you got the build from Anaconda.
Like a hello world. Do the multiplication.
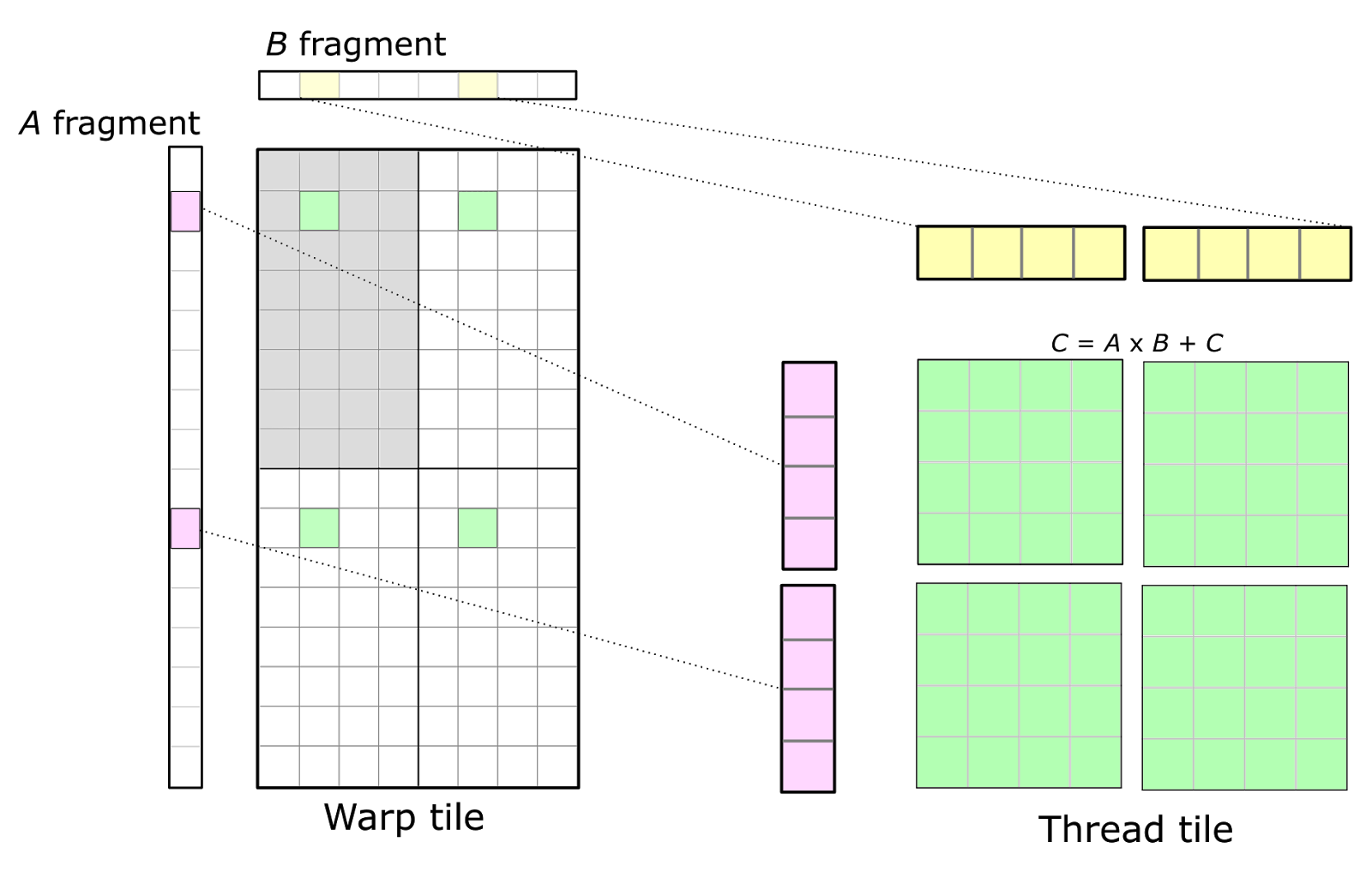
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
Github Kberkay Cuda Matrix Multiplication Matrix Multiplication On Gpu Using Shared Memory Considering Coalescing And Bank Conflicts

Lecture 13 Sparse Matrix Vector Multiplication And Cuda Libraries Ppt Download
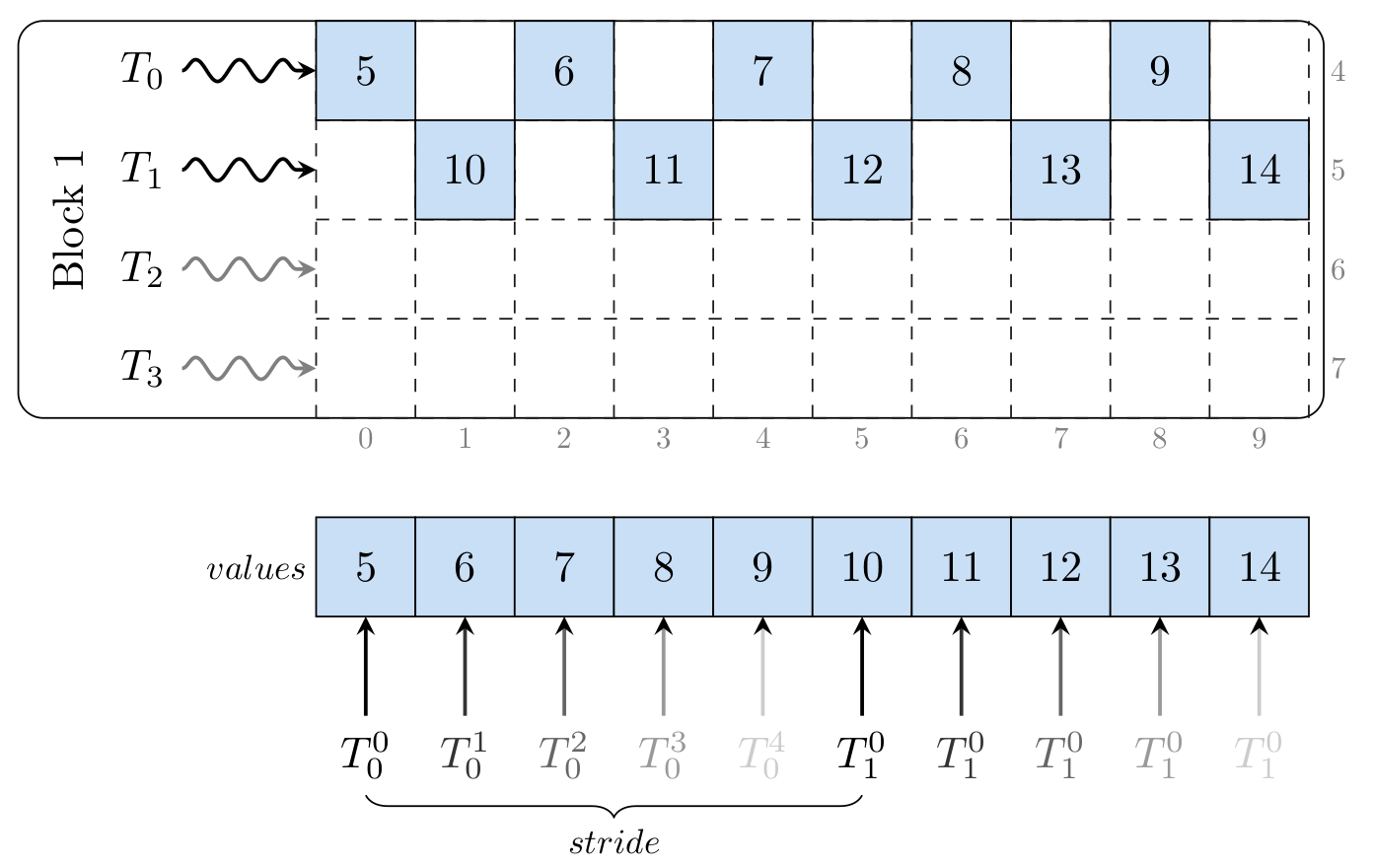
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
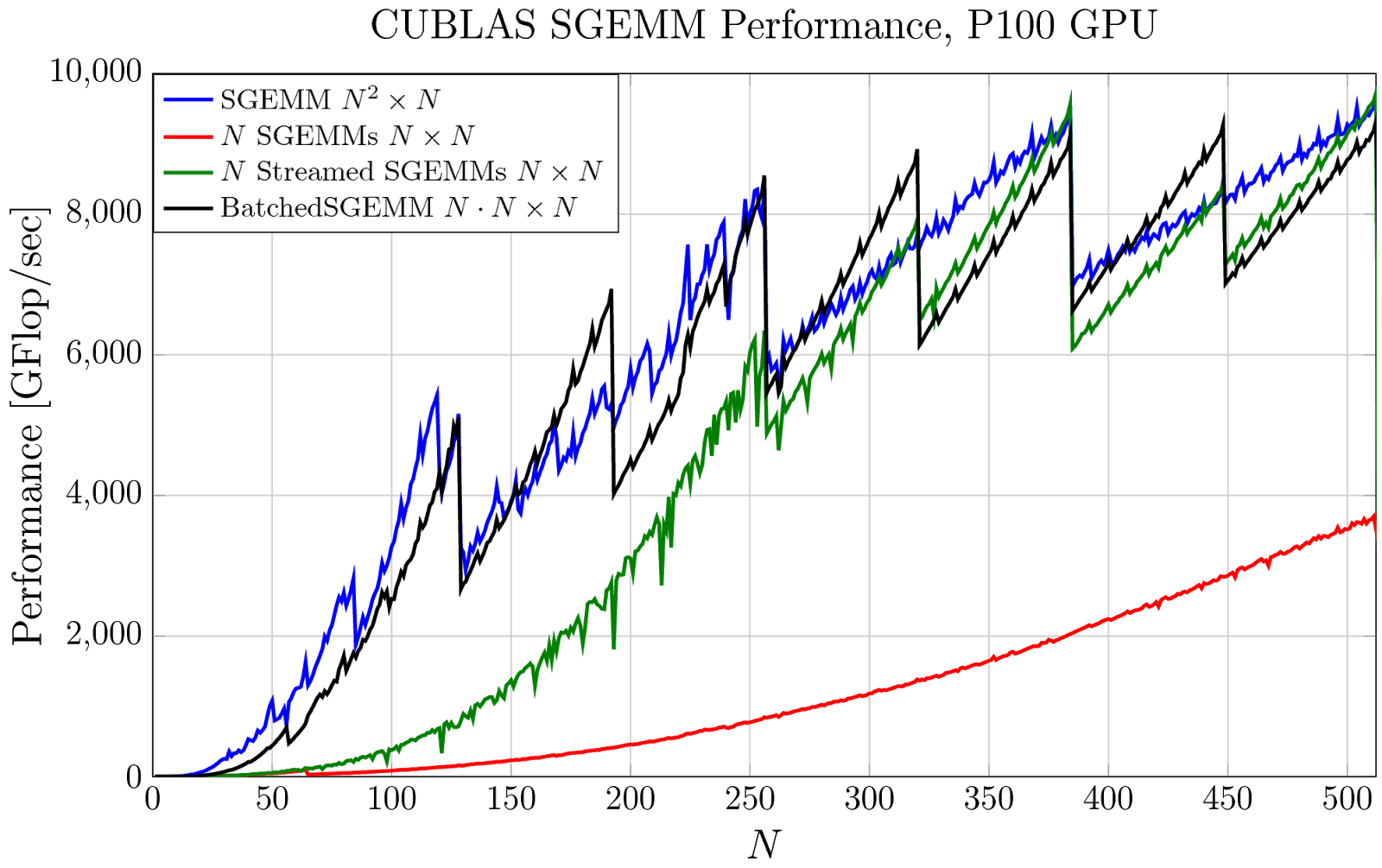
Pro Tip Cublas Strided Batched Matrix Multiply Nvidia Developer Blog
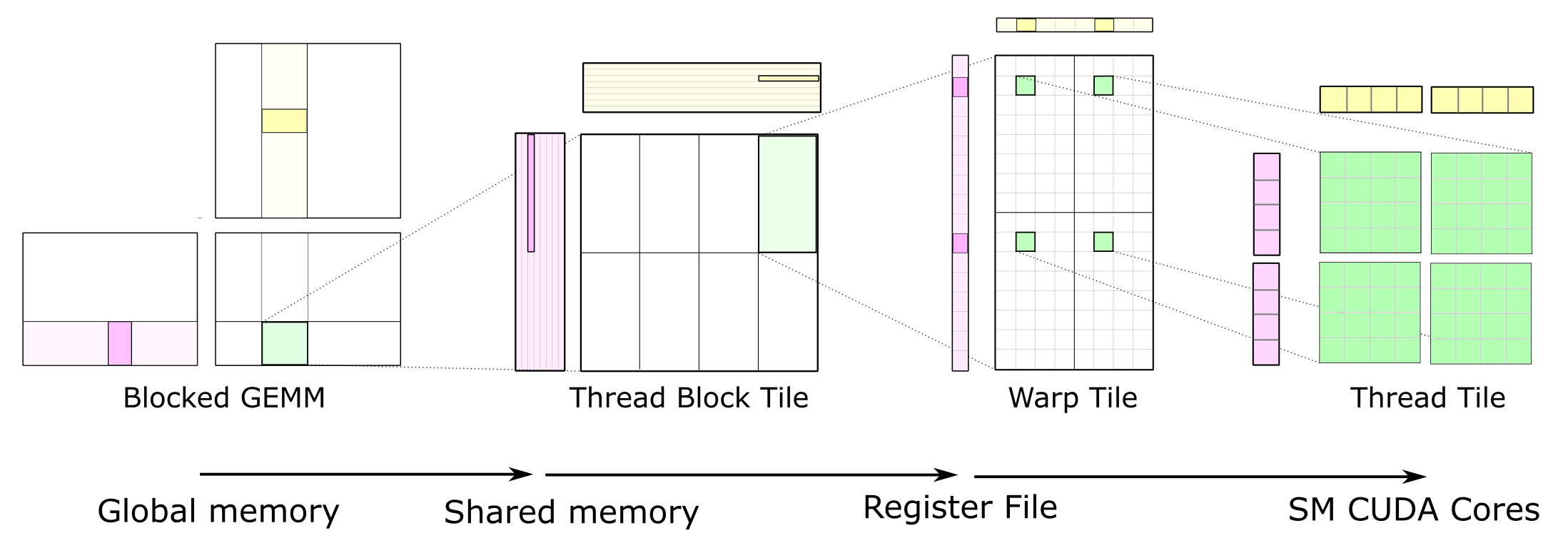
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
Exploiting Nvidia Ampere Structured Sparsity With Cusparselt

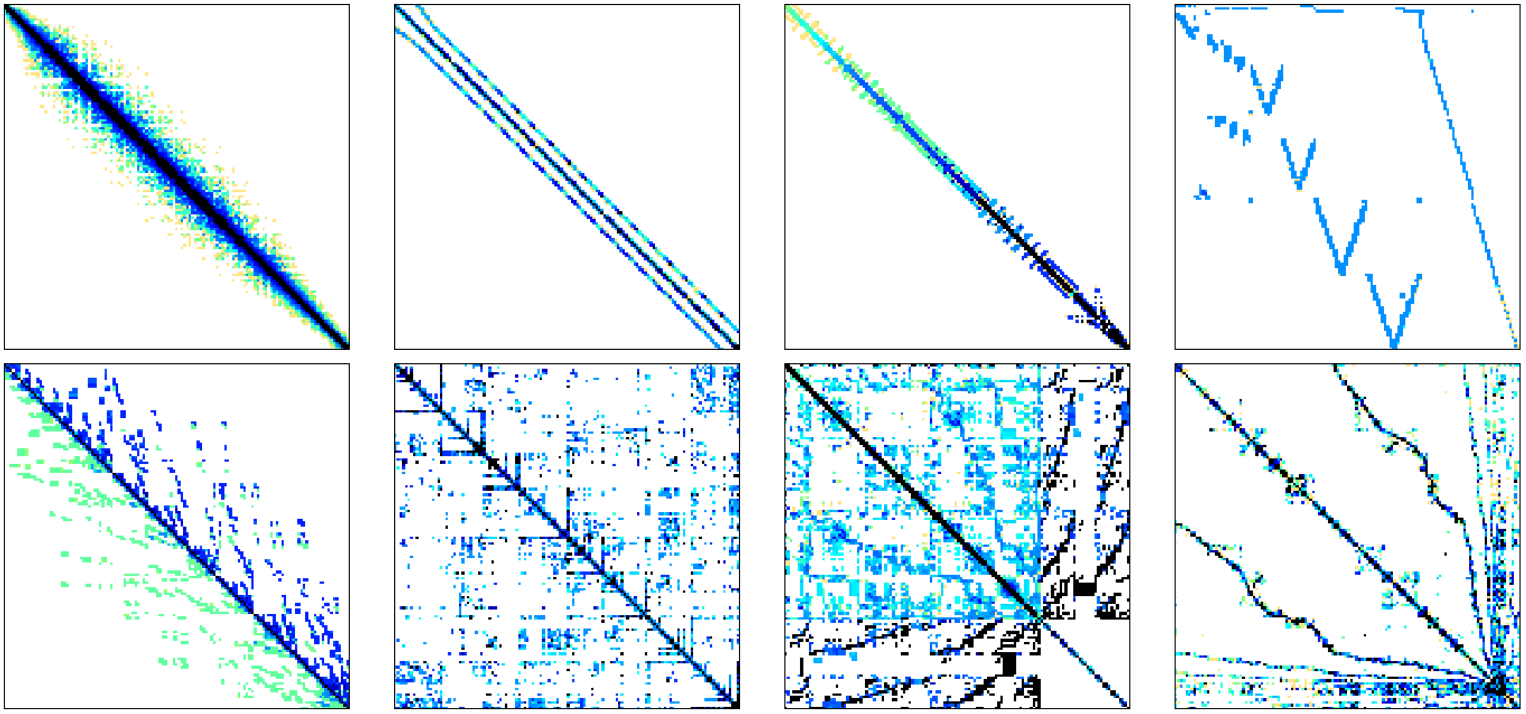
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Matrix Multiplication Cuda Eca Gpu 2018 2019
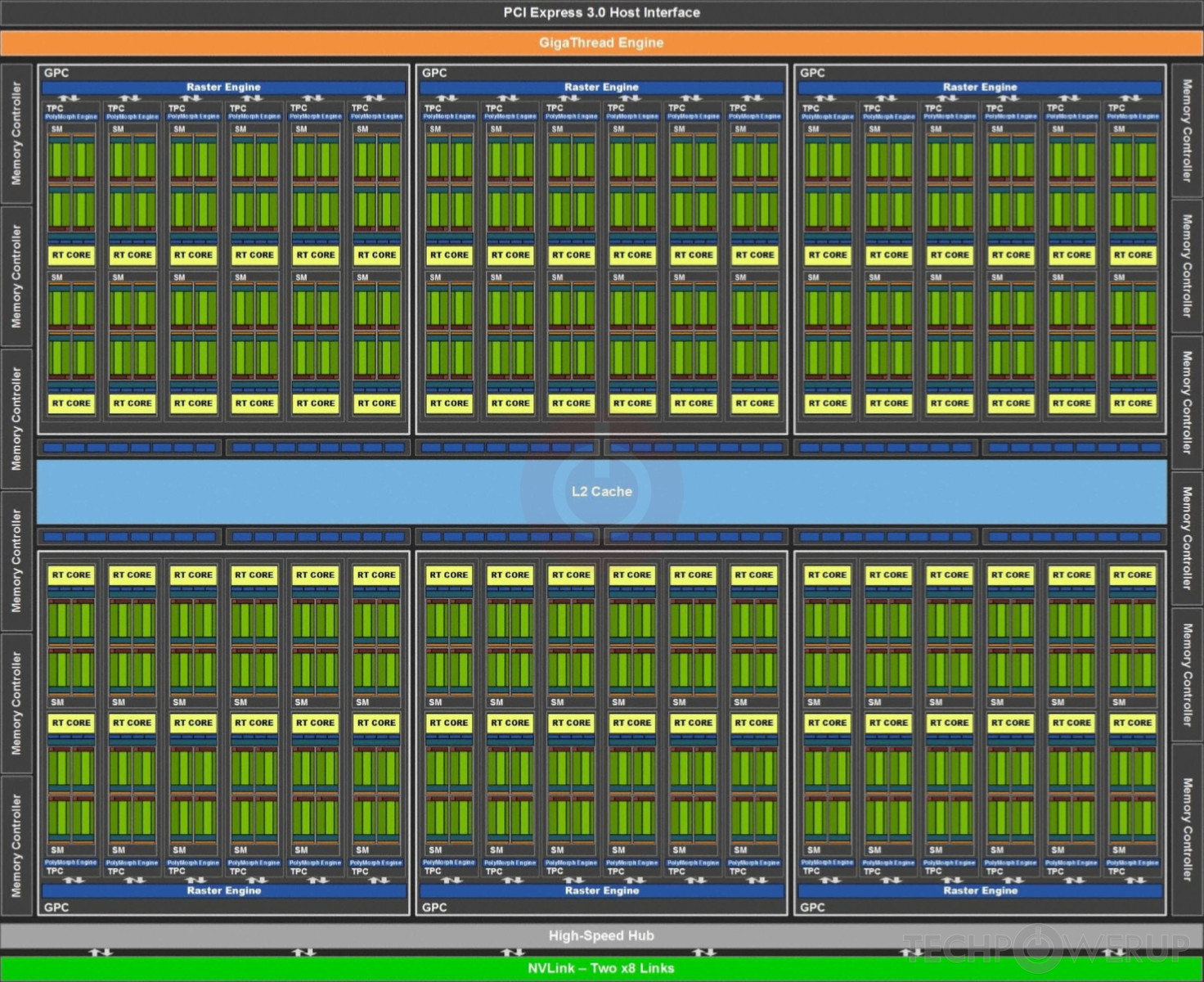
Cuda Kernels In Python

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
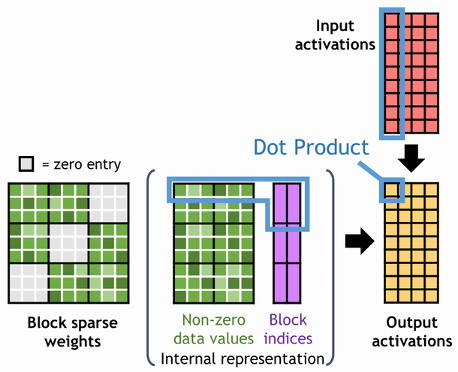
Accelerated Matrix Multiplication With Block Sparse Format And Nvidia Tensor Cores

Matrices Multiplying Gives Wrong Results On Cuda Stack Overflow
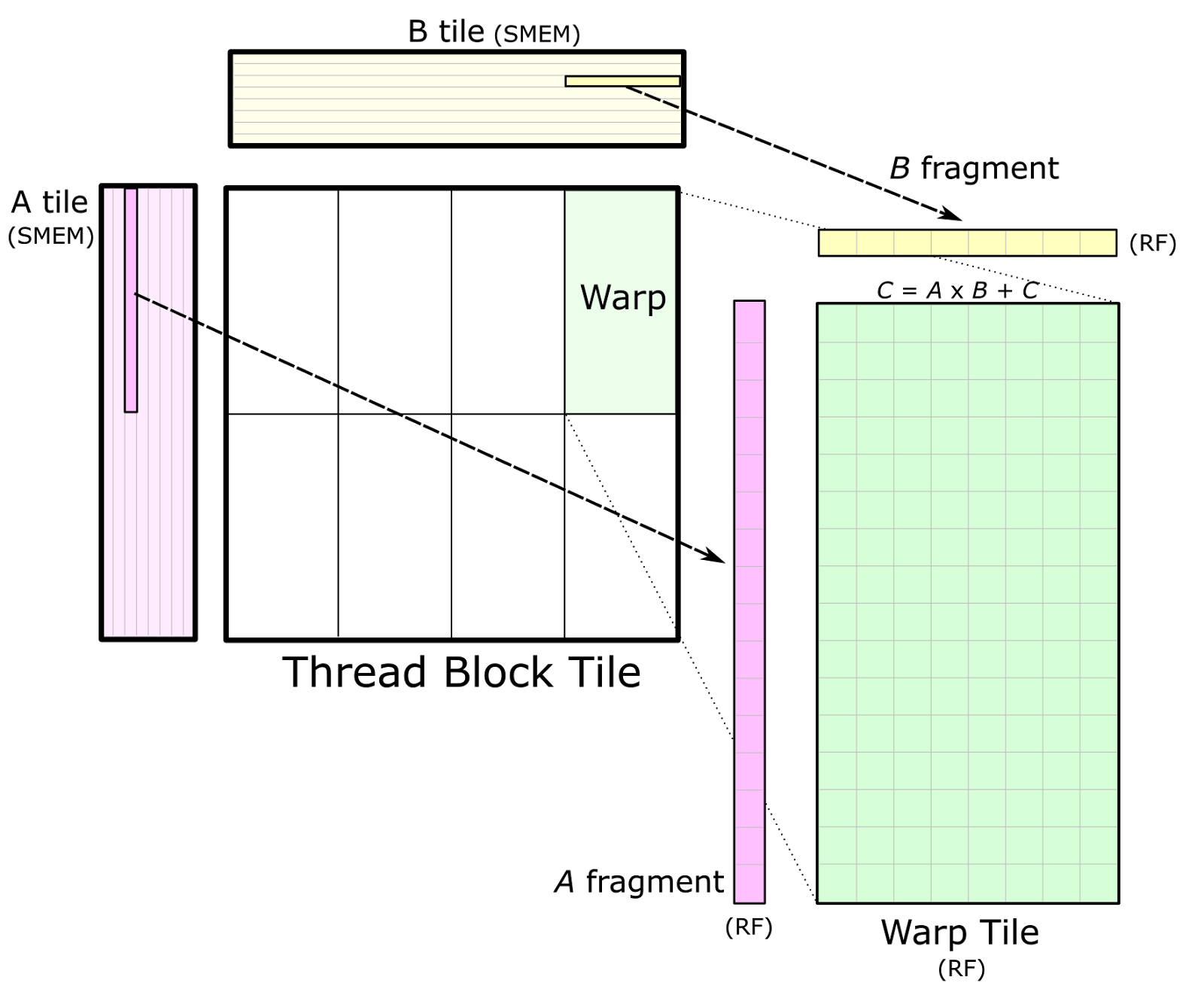
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
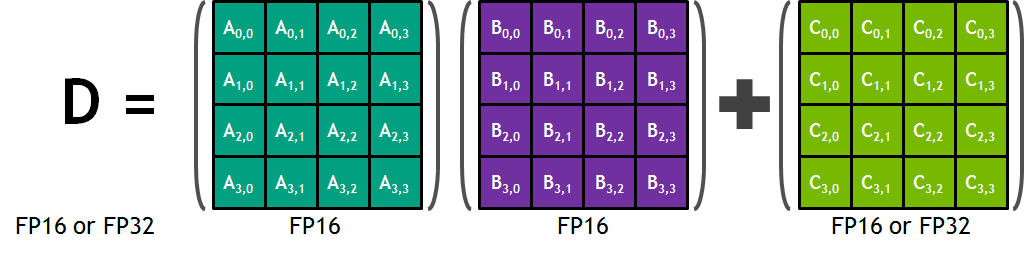
Programming Tensor Cores In Cuda 9 Nvidia Developer Blog

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Multiplication Kernel An Overview Sciencedirect Topics
Matrix Multiplication Cuda Eca Gpu 2018 2019