Non Square Matrix Multiplication Cuda
We use the example of Matrix Multiplication to introduce the basics of GPU computing in the CUDA environment. In this post I will show some of the performance gains achievable using shared memory.
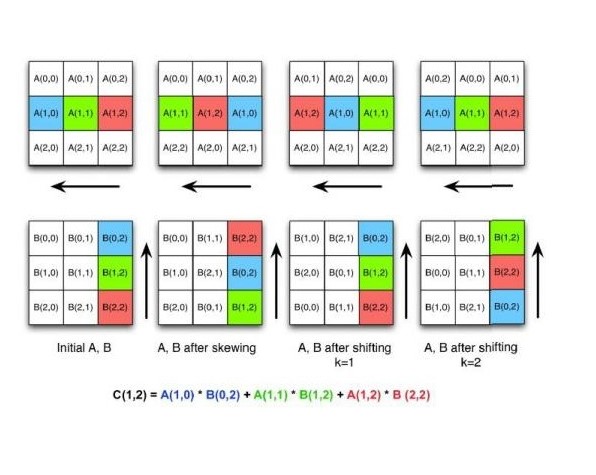
Cannon S Algorithm For Distributed Matrix Multiplication
Writefile matmul_naivecu define WIDTH 4096 __global__ void matmul_kernel float C float A float B int x blockIdx.

Non square matrix multiplication cuda. May I ask how would you implement non-square matrix multiplication. An Efficient Matrix Transpose in CUDA CC. But with matricies that do not have a size that is.
Non Square Matrix Multiplication in CUDA. 100003000 sized matrix multiplication. Test results following tests were carried out on a Tesla M2075 card lzhengchunclus10 liu aout.
Im new in CUDA parallel computing. The multiplication of two non square matrix is defined only if the number of columns in the first matrix is equal to the number of rows in the second matrix. For instance multiply a 4x3 by a 3x1 Thanks.
Float sum 00. Y block_size_y threadIdx. For example using a BLOCK_SIZE of 16 and two matrixes of 3200x3200 elements the results are correct.
Time elapsed on matrix multiplication of 1024x1024. For int k 0. In the CUDA examples if I use the sdk code its is valid for square matrixes.
I have a question. Specifically I will optimize a matrix transpose to show how to use shared memory to reorder strided. Execute the following cell to write our naive matrix multiplication kernel to a file name matmul_naivecu by pressing shiftenter.
CUDA C program for matrix Multiplication using Sharednon Shared memory Posted by Unknown at 0907 23 comments. Hi everyone its the first time I post here but im having problems with matrix multiplication on non square matrixes. Is it necessary for matrix dimension size to be 2n.
Please type in m n and k. One platform for doing so is NVIDIAs Compute Uni ed Device Architecture or CUDA. Matrix multiplication is under the list of time-consuming problems that require s huge computational resources to improve its speedup.
My last CUDA C post covered the mechanics of using shared memory including static and dynamic allocation. The code I use for matrix multiplications in CUDA lets me multiply both square and non square matrices however both Width and Height MUST be multiples of blocksize. Matrix multiplication in CUDA this is a toy program for learning CUDA some functions are reusable for other purposes.
You can write a multiplication algorithm for any size. It is assumed that the student is familiar with C programming but no other background is assumed. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK.
Tiled matrix-matrix multiplication with shared memory and matrix size which is non-multiple of the block size in that it does not use shared memory. The formula used to calculate elements of d_P is. A d_P element calculated by a thread is in blockIdxyblockDimythreadIdxy row and blockIdxxblockDimxthreadIdxx column.
Is it possible to compute non-squared matrix multiplication in CUDA. This paper focuses on matrix multiplication algorithm particularly square parallel matrix multiplication using Computer Unified Device Architecture CUDA programming model with C programming language. X block_size_x threadIdx.
However whe using the same BLOCK_SIZE and matrixA3200x1600 and. Int y blockIdx. So for example I can multiply 3 6 6 3 using blocksize3 but I cant multiply.

Multiplication Kernel An Overview Sciencedirect Topics
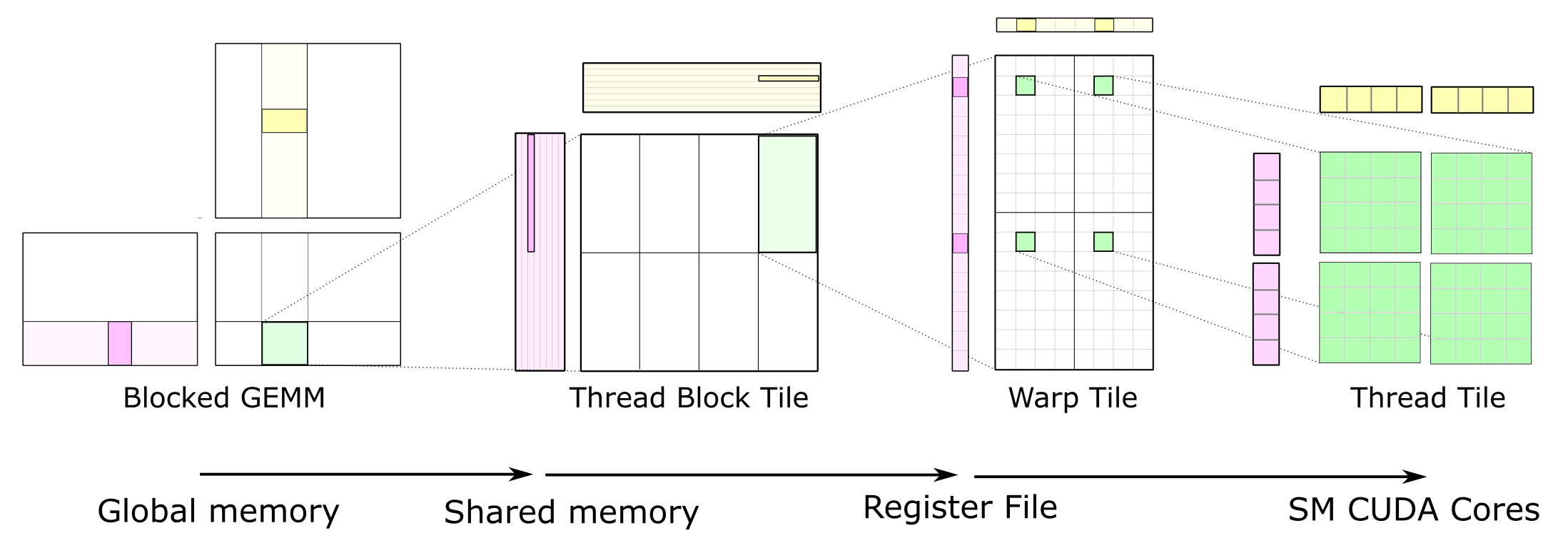
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
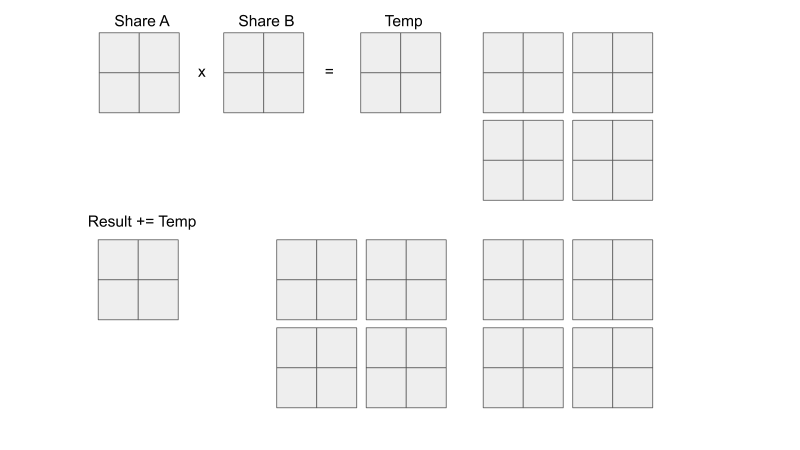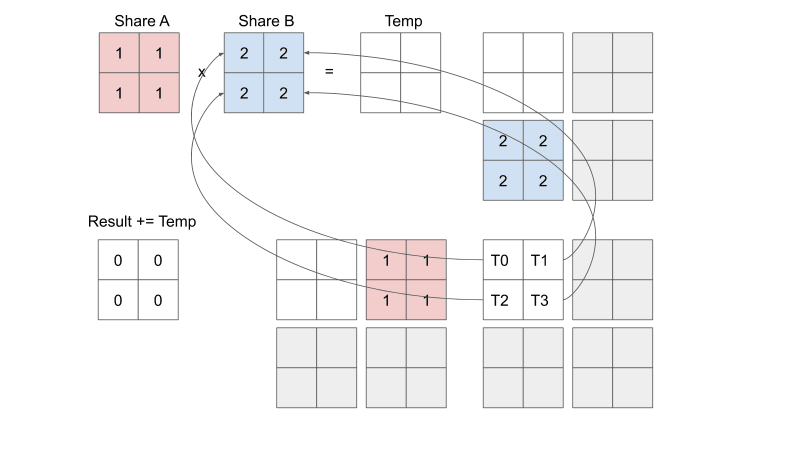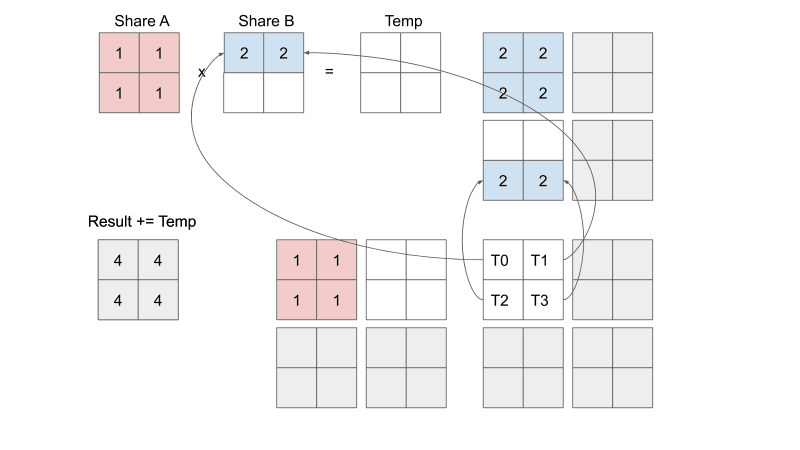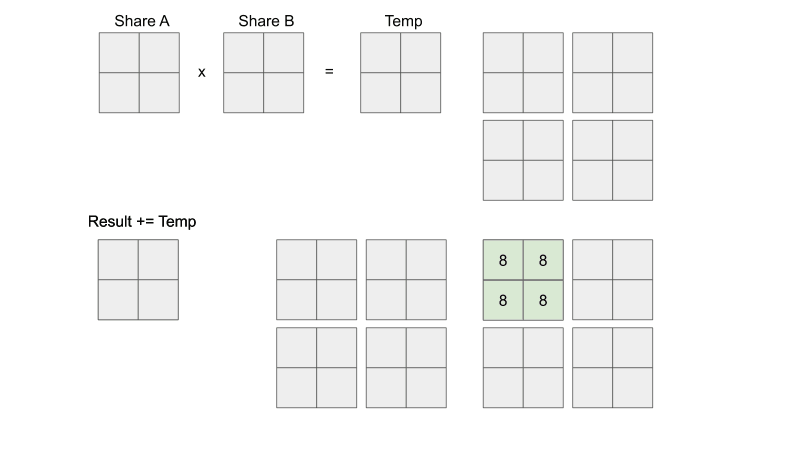
Tiled Matrix Multiplication
Diagram Of Matrix Multiplication Based On Cuda Download Scientific Diagram
Github Venkateshreddy74 Tiled Matrix Multiplication For Square And Non Square Matrices The Kernel Will Multiply A Matrix M By Another Matrix N Storing The Product Matrix P M N And P Will Not Necessarily Be Square Instead M Can Have

Pin On Useful Links
Github Kberkay Cuda Matrix Multiplication Matrix Multiplication On Gpu Using Shared Memory Considering Coalescing And Bank Conflicts

Is Matrix Multiplication Commutative Video Khan Academy
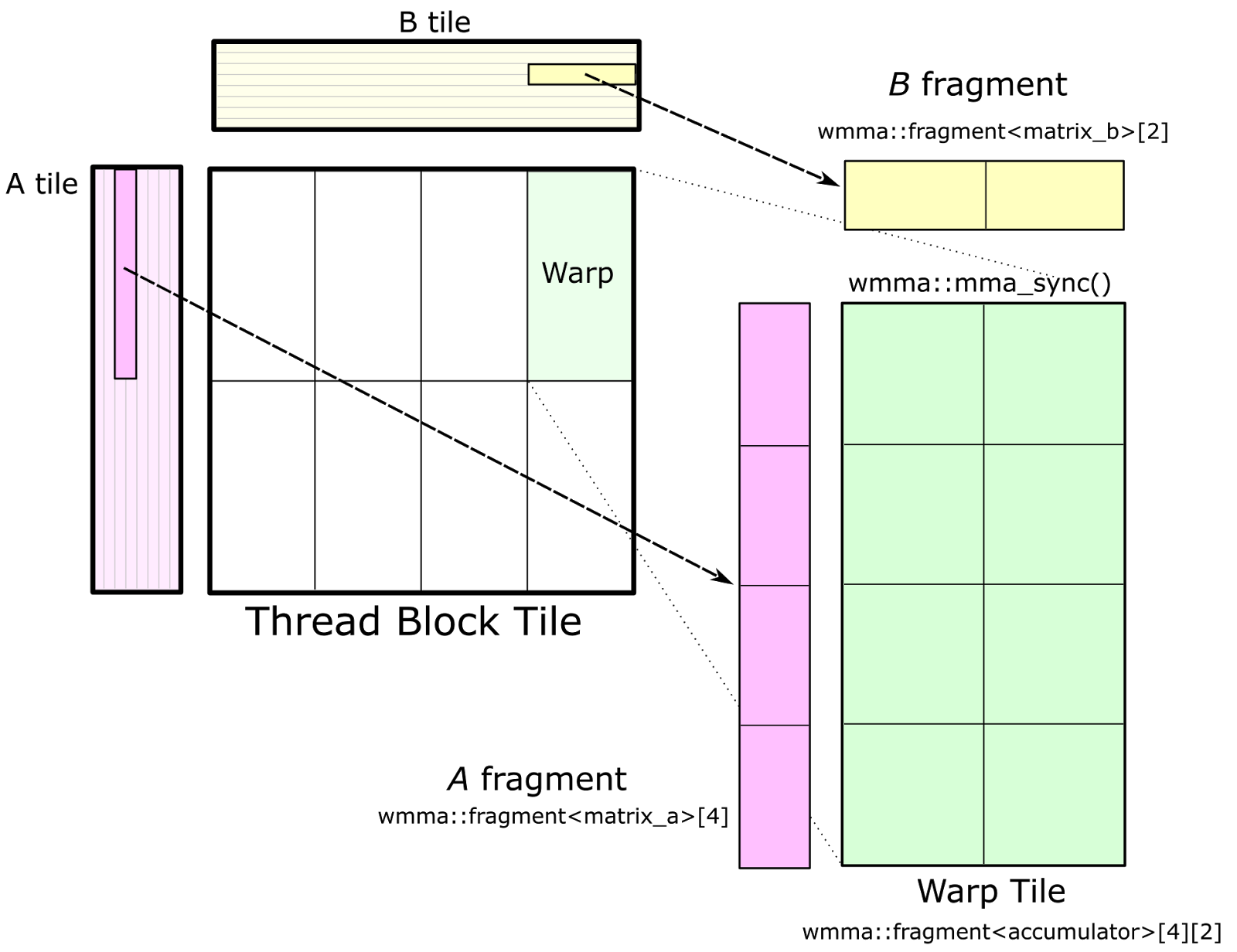
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
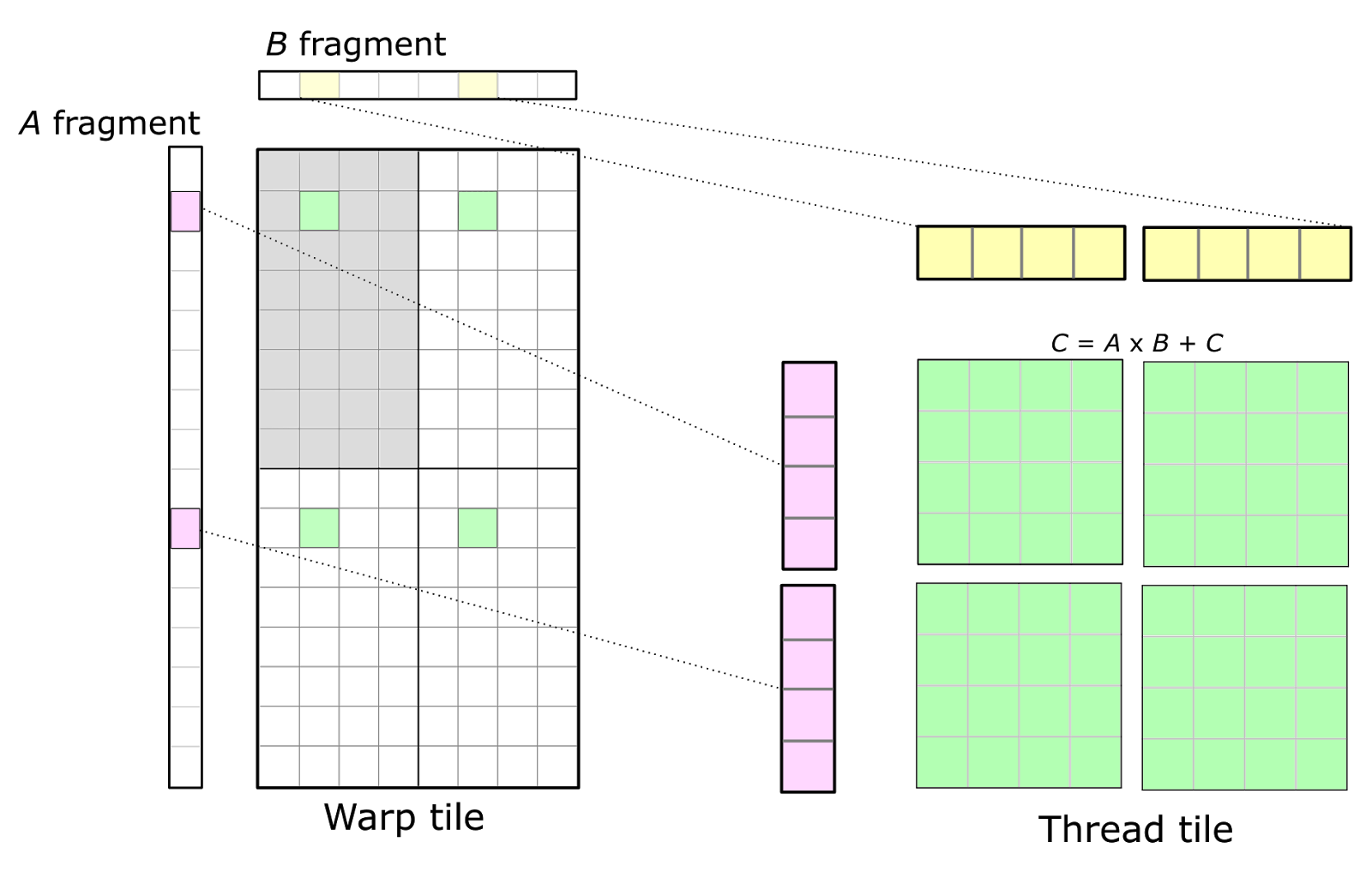
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
Cannon S Matrix Multiplication Algorithm Download Scientific Diagram
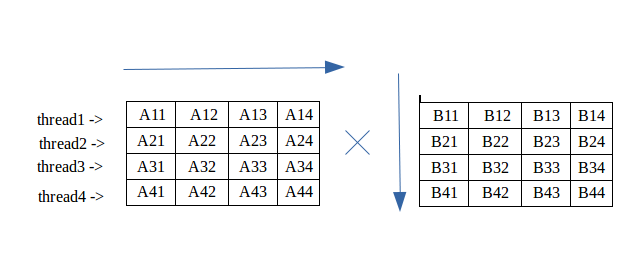
Multiplication Of Matrix Using Threads Geeksforgeeks
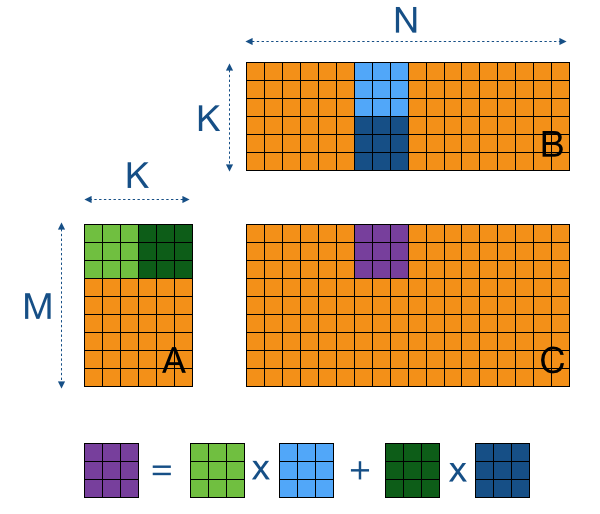
Opencl Matrix Multiplication Sgemm Tutorial

Matrices Multiplying Gives Wrong Results On Cuda Stack Overflow

Pin On Ai Hardware

Parallel Matrix Multiplication C Parallel Processing By Roshan Alwis Tech Vision Medium
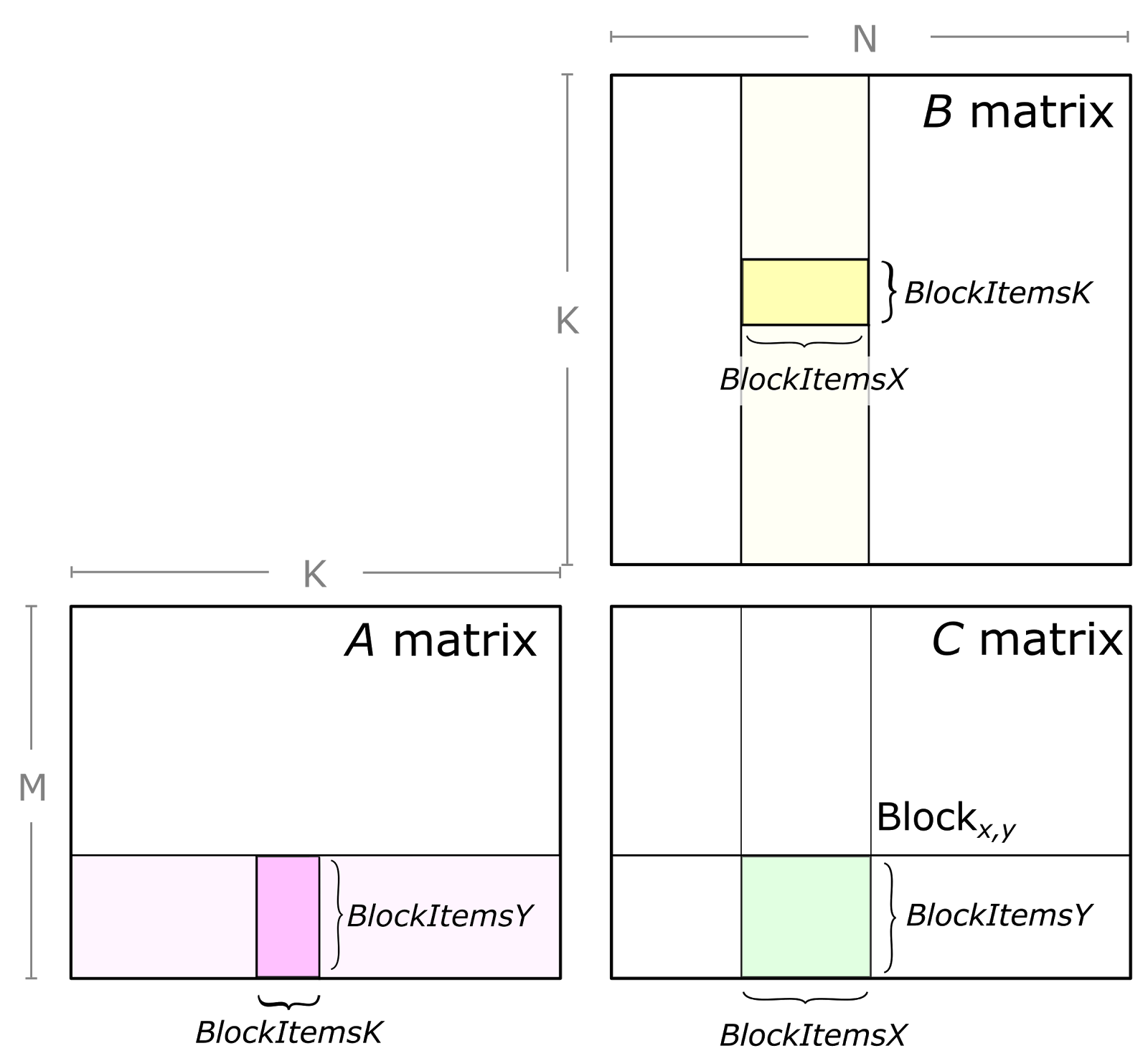
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

Matrix Multiplication Cuda Embedded Computer Architecture Gpu Assignment 2016 2017

An Alpaka Optimized Hierarchically Tiled Matrix Matrix Multiplication Download Scientific Diagram